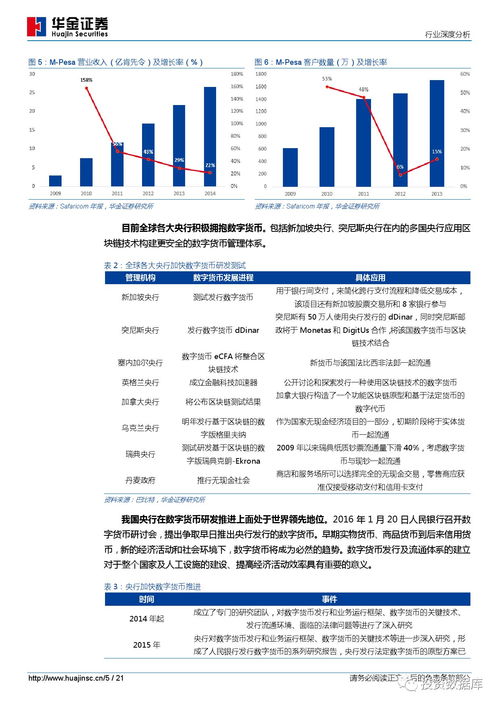
自动驾驶作为人工智能皇冠上的明珠,其核心驱动力之一是计算机视觉技术。从早期安霸(Ambarella)首席科学家Alberto Broggi的开拓性研究,到如今各大科技公司与车企的激烈角逐,计算机视觉始终是让汽车“看见”并理解世界的眼睛。本文将探讨计算机视觉在自动驾驶中的关键作用、主要技术构成以及当前的技术开发趋势。
一、 先驱与基石:Alberto Broggi与早期计算机视觉驾驶
意大利帕尔马大学的Alberto Broggi教授是自动驾驶领域的先驱之一。在20世纪90年代末至21世纪初,他领导的“ARGO”和“VIAC”等项目,展示了仅依靠单目摄像头和简单视觉算法实现车道保持、车辆跟踪等功能的可能性。这些早期实验虽受限于当时算力与算法,但奠定了视觉感知作为自动驾驶基础感知模态的地位。Broggi的工作证明了,通过模仿人类视觉,机器同样可以解读道路环境,这为后续深度学习和多传感器融合的爆炸式发展指明了方向。
二、 自动驾驶的“视觉工具箱”:核心计算机视觉技术
现代自动驾驶系统依赖一系列复杂且相互协同的计算机视觉技术,主要包括:
- 物体检测与识别:这是最核心的能力。利用卷积神经网络(CNN)等深度学习模型,系统能实时检测并分类图像中的关键物体,如车辆、行人、骑行者、交通标志、信号灯等。YOLO、SSD、Faster R-CNN等算法在此领域占据主导。
- 语义分割:不仅识别物体,还为图像中的每一个像素分配一个类别标签(如道路、天空、建筑、植被),从而生成对场景的密集理解。这对于理解可行驶区域和复杂场景边界至关重要。
- 深度估计与3D感知:单目摄像头可以通过学习来估计物体距离,而立体视觉(多摄像头)和基于视觉的SLAM(同步定位与地图构建)技术则能更精确地重建三维场景结构,为路径规划提供空间信息。
- 目标跟踪:在连续帧中跟踪被检测物体的运动轨迹,预测其未来位置和行为意图(如行人是否要横穿马路),这是实现安全决策的关键。
- 车道线与可行驶区域检测:专门用于识别车道标记、道路边缘和边界,是保持车辆在车道内行驶的基础。
- 视觉里程计(VO)与SLAM:仅通过摄像头序列来估计车辆自身的运动并同时构建周围环境地图,在GPS信号弱或无高精地图区域尤为重要。
三、 技术开发现状与融合趋势
当前自动驾驶的计算机视觉技术开发正朝着更智能、更可靠、更高效的方向演进:
- 从纯视觉到多传感器融合:尽管特斯拉等公司推崇“视觉优先”甚至“纯视觉”方案,但行业主流趋势是将摄像头与激光雷达、毫米波雷达进行前融合或后融合。视觉提供丰富的纹理和颜色信息,雷达提供精确的距离和速度,激光雷达提供精准的三维点云,三者互补能极大提升系统在恶劣天气和复杂场景下的鲁棒性。
- 端到端学习与Transformer架构:传统流水线式处理(检测-跟踪-规划)正受到端到端深度学习的挑战。通过将原始传感器数据直接映射到控制指令,系统可能学习到更优的驾驶策略。源自自然语言处理的Transformer模型(如Vision Transformer)因其强大的全局建模能力,正在图像识别和BEV(鸟瞰图)感知生成任务中取代部分CNN,实现更统一的环境表征。
- 仿真与数据引擎:计算机视觉模型的训练依赖海量、高质量、多样化的标注数据。开发重点也包括构建强大的数据自动化流水线(如自动标注、合成数据生成)和超高逼真的仿真环境,以覆盖长尾场景(如极端天气、罕见事故),加速算法迭代。
- 边缘计算与芯片优化:自动驾驶对实时性要求极高。以安霸(Ambarella)为代表的芯片公司,专注于开发低功耗、高性能的AI视觉处理SoC(系统级芯片),将复杂的视觉算法高效部署在车载边缘计算单元上,实现低延迟的实时感知。
四、 挑战与未来展望
尽管进步巨大,挑战依然存在:视觉系统在极端光照(强光、黑夜)、恶劣天气(雨、雪、雾)下的性能下降;对未知或对抗性样本的脆弱性;以及感知结果如何与决策规划模块进行安全、可解释的交互。
计算机视觉在自动驾驶中的发展将与神经科学(借鉴人脑视觉机制)、因果推断(理解事件因果关系)以及具身AI(视觉与行动更紧密结合)等前沿领域交叉。从Alberto Broggi的单目摄像头实验,到今天软硬件一体的复杂智能系统,计算机视觉技术无疑是自动驾驶汽车驶向未来的核心引擎,它的每一次突破,都让我们离安全、高效的无人驾驶世界更近一步。